ZFS storage driver
ZFS is a next generation filesystem that supports many advanced storage technologies such as volume management, snapshots, checksumming, compression and deduplication, replication and more.
It was created by Sun Microsystems (now Oracle Corporation) and is open sourced under the CDDL license. Due to licensing incompatibilities between the CDDL and GPL, ZFS cannot be shipped as part of the mainline Linux kernel. However, the ZFS On Linux (ZoL) project provides an out-of-tree kernel module and userspace tools which can be installed separately.
The ZFS on Linux (ZoL) port is healthy and maturing. However, at this point in
time it is not recommended to use the zfs Docker storage driver for production
use unless you have substantial experience with ZFS on Linux.
メモThere is also a FUSE implementation of ZFS on the Linux platform. This is not recommended. The native ZFS driver (ZoL) is more tested, has better performance, and is more widely used. The remainder of this document refers to the native ZoL port.
Prerequisites
- ZFS requires one or more dedicated block devices, preferably solid-state drives (SSDs).
- The
/var/lib/docker/directory must be mounted on a ZFS-formatted filesystem. - Changing the storage driver makes any containers you have already
created inaccessible on the local system. Use
docker saveto save containers, and push existing images to Docker Hub or a private repository, so that you do not need to re-create them later.
メモThere is no need to use
MountFlags=slavebecausedockerdandcontainerdare in different mount namespaces.
Configure Docker with the zfs storage driver
Stop Docker.
Copy the contents of
/var/lib/docker/to/var/lib/docker.bkand remove the contents of/var/lib/docker/.$ sudo cp -au /var/lib/docker /var/lib/docker.bk $ sudo rm -rf /var/lib/docker/*Create a new
zpoolon your dedicated block device or devices, and mount it into/var/lib/docker/. Be sure you have specified the correct devices, because this is a destructive operation. This example adds two devices to the pool.$ sudo zpool create -f zpool-docker -m /var/lib/docker /dev/xvdf /dev/xvdgThe command creates the
zpooland names itzpool-docker. The name is for display purposes only, and you can use a different name. Check that the pool was created and mounted correctly usingzfs list.$ sudo zfs list NAME USED AVAIL REFER MOUNTPOINT zpool-docker 55K 96.4G 19K /var/lib/dockerConfigure Docker to use
zfs. Edit/etc/docker/daemon.jsonand set thestorage-drivertozfs. If the file was empty before, it should now look like this:{ "storage-driver": "zfs" }Save and close the file.
Start Docker. Use
docker infoto verify that the storage driver iszfs.$ sudo docker info Containers: 0 Running: 0 Paused: 0 Stopped: 0 Images: 0 Server Version: 17.03.1-ce Storage Driver: zfs Zpool: zpool-docker Zpool Health: ONLINE Parent Dataset: zpool-docker Space Used By Parent: 249856 Space Available: 103498395648 Parent Quota: no Compression: off <...>
Manage zfs
Increase capacity on a running device
To increase the size of the zpool, you need to add a dedicated block device to
the Docker host, and then add it to the zpool using the zpool add command:
$ sudo zpool add zpool-docker /dev/xvdh
Limit a container's writable storage quota
If you want to implement a quota on a per-image/dataset basis, you can set the
size storage option to limit the amount of space a single container can use
for its writable layer.
Edit /etc/docker/daemon.json and add the following:
{
"storage-driver": "zfs",
"storage-opts": ["size=256M"]
}See all storage options for each storage driver in the daemon reference documentation
Save and close the file, and restart Docker.
How the zfs storage driver works
ZFS uses the following objects:
- filesystems: thinly provisioned, with space allocated from the
zpoolon demand. - snapshots: read-only space-efficient point-in-time copies of filesystems.
- clones: Read-write copies of snapshots. Used for storing the differences from the previous layer.
The process of creating a clone:
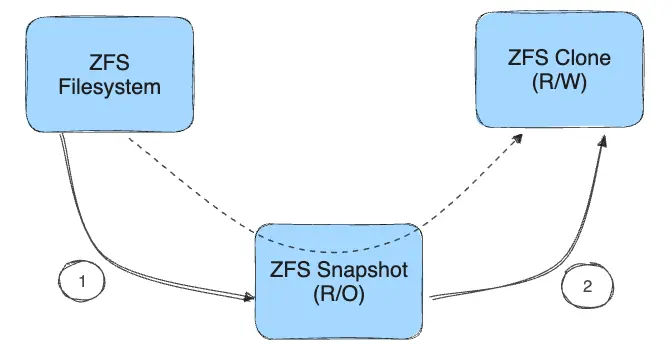
- A read-only snapshot is created from the filesystem.
- A writable clone is created from the snapshot. This contains any differences from the parent layer.
Filesystems, snapshots, and clones all allocate space from the underlying
zpool.
Image and container layers on-disk
Each running container's unified filesystem is mounted on a mount point in
/var/lib/docker/zfs/graph/. Continue reading for an explanation of how the
unified filesystem is composed.
Image layering and sharing
The base layer of an image is a ZFS filesystem. Each child layer is a ZFS clone based on a ZFS snapshot of the layer below it. A container is a ZFS clone based on a ZFS Snapshot of the top layer of the image it's created from.
The diagram below shows how this is put together with a running container based on a two-layer image.
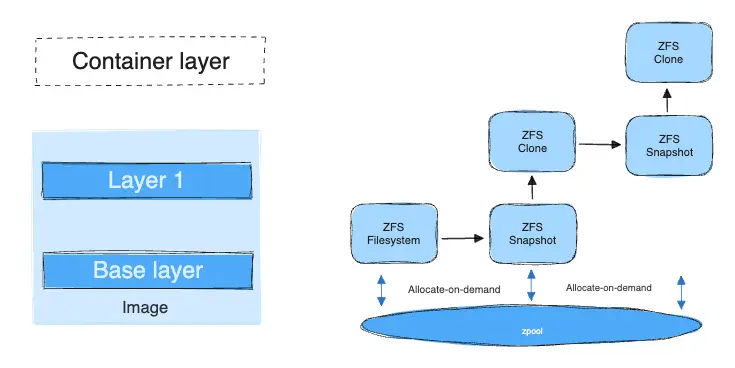
When you start a container, the following steps happen in order:
The base layer of the image exists on the Docker host as a ZFS filesystem.
Additional image layers are clones of the dataset hosting the image layer directly below it.
In the diagram, "Layer 1" is added by taking a ZFS snapshot of the base layer and then creating a clone from that snapshot. The clone is writable and consumes space on-demand from the zpool. The snapshot is read-only, maintaining the base layer as an immutable object.
When the container is launched, a writable layer is added above the image.
In the diagram, the container's read-write layer is created by making a snapshot of the top layer of the image (Layer 1) and creating a clone from that snapshot.
As the container modifies the contents of its writable layer, space is allocated for the blocks that are changed. By default, these blocks are 128k.
How container reads and writes work with zfs
Reading files
Each container's writable layer is a ZFS clone which shares all its data with the dataset it was created from (the snapshots of its parent layers). Read operations are fast, even if the data being read is from a deep layer. This diagram illustrates how block sharing works:
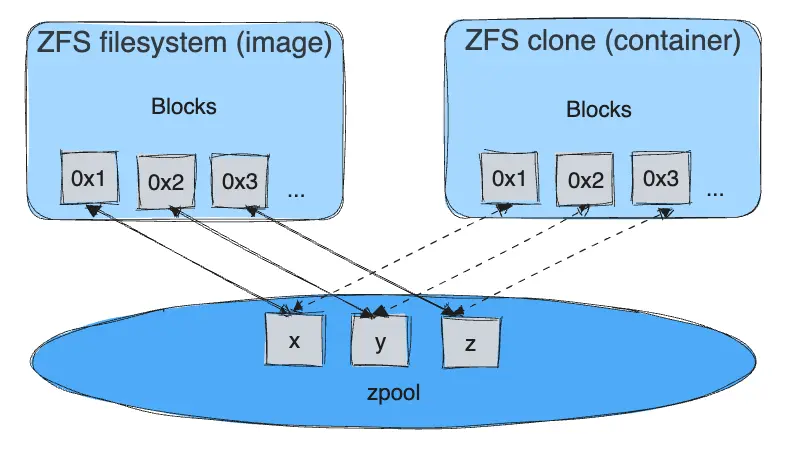
Writing files
Writing a new file: space is allocated on demand from the underlying zpool
and the blocks are written directly into the container's writable layer.
Modifying an existing file: space is allocated only for the changed blocks, and those blocks are written into the container's writable layer using a copy-on-write (CoW) strategy. This minimizes the size of the layer and increases write performance.
Deleting a file or directory:
- When you delete a file or directory that exists in a lower layer, the ZFS driver masks the existence of the file or directory in the container's writable layer, even though the file or directory still exists in the lower read-only layers.
- If you create and then delete a file or directory within the container's
writable layer, the blocks are reclaimed by the
zpool.
ZFS and Docker performance
There are several factors that influence the performance of Docker using the
zfs storage driver.
Memory: Memory has a major impact on ZFS performance. ZFS was originally designed for large enterprise-grade servers with a large amount of memory.
ZFS Features: ZFS includes a de-duplication feature. Using this feature may save disk space, but uses a large amount of memory. It is recommended that you disable this feature for the
zpoolyou are using with Docker, unless you are using SAN, NAS, or other hardware RAID technologies.ZFS Caching: ZFS caches disk blocks in a memory structure called the adaptive replacement cache (ARC). The Single Copy ARC feature of ZFS allows a single cached copy of a block to be shared by multiple clones of a With this feature, multiple running containers can share a single copy of a cached block. This feature makes ZFS a good option for PaaS and other high-density use cases.
Fragmentation: Fragmentation is a natural byproduct of copy-on-write filesystems like ZFS. ZFS mitigates this by using a small block size of 128k. The ZFS intent log (ZIL) and the coalescing of writes (delayed writes) also help to reduce fragmentation. You can monitor fragmentation using
zpool status. However, there is no way to defragment ZFS without reformatting and restoring the filesystem.Use the native ZFS driver for Linux: The ZFS FUSE implementation is not recommended, due to poor performance.
Performance best practices
Use fast storage: Solid-state drives (SSDs) provide faster reads and writes than spinning disks.
Use volumes for write-heavy workloads: Volumes provide the best and most predictable performance for write-heavy workloads. This is because they bypass the storage driver and do not incur any of the potential overheads introduced by thin provisioning and copy-on-write. Volumes have other benefits, such as allowing you to share data among containers and persisting even when no running container is using them.