Prometheus を用いた Docker メトリックスの収集
読む時間の目安: 5 分
Prometheus はシステム監視や警告を行うオープンソースのツールキットです。 この Prometheus の対象として Docker を設定することができます。 ここでは Docker の設定、Docker コンテナーとしての Prometheus の設定、Prometheus を使った Docker インスタンスの監視について示します。
警告 利用可能なメトリックスおよびその名称は、現在開発中のものであるため、随時変更されます。
現時点において監視できる対象は Docker そのものです。 Docker ターゲットとしてアプリケーションを監視することは、今のところできません。
Docker の設定
Docker デーモンを Prometheus のターゲットとして設定するには、metrics-addressを指定する必要があります。
これを行う一番良い方法はdaemon.jsonに記述することです。
デフォルトにおいてdaemon.jsonは以下に示すいずれかのディレクトリにあります。
もしこのファイルが存在していない場合は、新規に生成します。
- Linux:
/etc/docker/daemon.json - Windows Server:
C:\ProgramData\docker\config\daemon.json - Docker Desktop for Mac / Docker Desktop for Windows: ツールバーの Docker アイコンをクリック、Preferences、Daemon を選択。Advanced をクリック。
このファイルが空であった場合は、以下の内容を貼り付けます。
{
"metrics-addr" : "127.0.0.1:9323",
"experimental" : true
}
このファイルが空でなかった場合は、上の 2 つのキーを追加します。
書き加えた結果は正しい JSON フォーマットでなければなりません。
最終行を除き、各行の終わりはカンマ(,)が必要です。
ファイルを保存します。 また Docker Desktop for Mac や Docker Desktop for Windows を利用している場合は、設定を保存します。 そして Docker を再起動します。
これにより Docker は、Prometheus 互換メトリックスをポート 9323 番にて公開することになります。
Prometheus の設定と実行
Docker swarm 上の Docker サービスとして Prometheus を実行します。
前提条件
1 つまたは複数の Docker Engine が参加して 1 つの Docker Swarm が形成されていること。 つまり 1 つのマネージャー上から
docker swarm initを実行しているか、あるいは他のマネージャーやワーカーノードからdocker swarm joinを実行していること。Prometheus イメージをプルできるように、インターネット接続ができていること。
以下の設定ファイルの内容をいずれかコピーして、(Linux や Mac の場合)/tmp/prometheus.yml、(Windows の場合)C:\tmp\prometheus.ymlに保存してください。
これは Prometheus のごく普通の設定ファイルです。
ただしファイルの最後段には Docker の処理定義を加えています。
Docker Desktop for Mac や Docker Desktop for Windows では、多少異なる設定が必要となります。
# グローバルな設定。
global:
scrape_interval: 15s # 情報を取り出す(scrapeする)間隔を15秒ごとに。デフォルトは1分ごと。
evaluation_interval: 15s # 15秒ごとにルールを評価。デフォルトは1分ごと。
# scrape_timeout はグローバルなデフォルト値(10s)に設定。
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# ルールを一度ロードし、以降はグローバルな 'evaluation_interval' に従って定期的に評価。
rule_files:
# - "first.rules"
# - "second.rules"
# A scrape configuration containing exactly one endpoint to scrape:
# ここが Prometheus の設定そのもの。
scrape_configs:
# この設定から取得されるすべてのタイムシリーズにて、ジョブ名は`job=<job_name>`というラベルとして追加。
- job_name: 'prometheus'
# metrics_path のデフォルトを '/metrics' に。
# スキームのデフォルトを 'http' に。
static_configs:
- targets: ['localhost:9090']
- job_name: 'docker'
# metrics_path のデフォルトを '/metrics' に。
# スキームのデフォルトを 'http' に。
static_configs:
- targets: ['localhost:9323']
# グローバルな設定。
global:
scrape_interval: 15s # 情報を取り出す(scrapeする)間隔を15秒ごとに。デフォルトは1分ごと。
evaluation_interval: 15s # 15秒ごとにルールを評価。デフォルトは1分ごと。
# scrape_timeout はグローバルなデフォルト値(10s)に設定。
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# ルールを一度ロードし、以降はグローバルな 'evaluation_interval' に従って定期的に評価。
rule_files:
# - "first.rules"
# - "second.rules"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# この設定から取得されるすべてのタイムシリーズにて、ジョブ名は`job=<job_name>`というラベルとして追加。
- job_name: 'prometheus'
# metrics_path のデフォルトを '/metrics' に。
# スキームのデフォルトを 'http' に。
static_configs:
- targets: ['host.docker.internal:9090'] # Docker Desktop for Mac においてのみ動作。
- job_name: 'docker'
# metrics_path のデフォルトを '/metrics' に。
# スキームのデフォルトを 'http' に。
static_configs:
- targets: ['docker.for.mac.host.internal:9323']
# グローバルな設定
global:
scrape_interval: 15s # 情報を取り出す(scrapeする)間隔を15秒ごとに。デフォルトは1分ごと。
evaluation_interval: 15s # 15秒ごとにルールを評価。デフォルトは1分ごと。
# scrape_timeout はグローバルなデフォルト値(10s)に設定。
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# ルールを一度ロードし、以降はグローバルな 'evaluation_interval' に従って定期的に評価
rule_files:
# - "first.rules"
# - "second.rules"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# この設定から取得されるすべてのタイムシリーズにて、ジョブ名は`job=<job_name>`というラベルとして追加。
- job_name: 'prometheus'
# metrics_path のデフォルトを '/metrics' に。
# スキームのデフォルトを 'http' に。
static_configs:
- targets: ['host.docker.internal:9090'] # Docker Desktop for Windows でのみ動作。
- job_name: 'docker'
# metrics_path のデフォルトを '/metrics' に。
# スキームのデフォルトを 'http' に。
static_configs:
- targets: ['192.168.65.1:9323']
次にこの設定を使って、単一レプリカとなる Prometheus サービスを起動します。
$ docker service create --replicas 1 --name my-prometheus \
--mount type=bind,source=/tmp/prometheus.yml,destination=/etc/prometheus/prometheus.yml \
--publish published=9090,target=9090,protocol=tcp \
prom/prometheus
$ docker service create --replicas 1 --name my-prometheus \
--mount type=bind,source=/tmp/prometheus.yml,destination=/etc/prometheus/prometheus.yml \
--publish published=9090,target=9090,protocol=tcp \
prom/prometheus
PS C:\> docker service create --replicas 1 --name my-prometheus
--mount type=bind,source=C:/tmp/prometheus.yml,destination=/etc/prometheus/prometheus.yml
--publish published=9090,target=9090,protocol=tcp
prom/prometheus
http://localhost:9090/targets/ にアクセスして Docker ターゲットが一覧表示されていることを確認します。
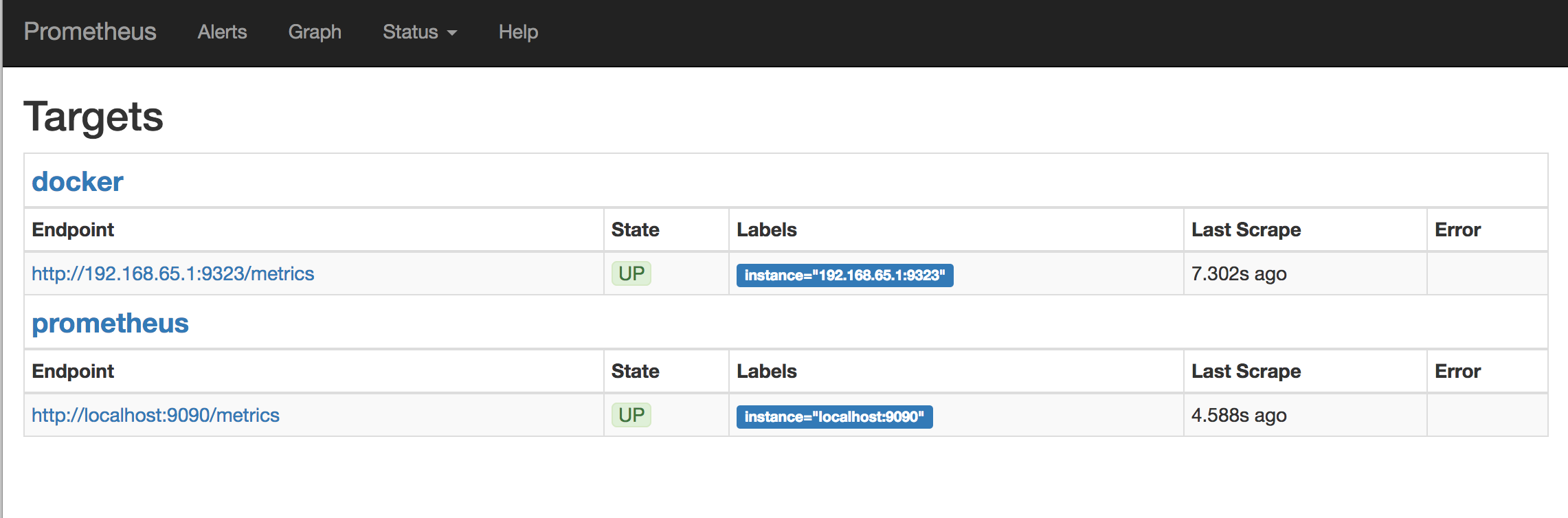
Docker Desktop for Mac や Docker Desktop for Windows を利用している場合は、エンドポイント URL に直接アクセスすることはできません。
Prometheus の利用
グラフを生成します。
Prometheus UI 画面の Graphs リンクをクリックします。
そして Execute ボタンの右にあるコンボボックスからメトリックを選び Execute をクリックします。
以下に示すスクリーンショットはengine_daemon_network_actions_seconds_countに対するグラフを示しています。
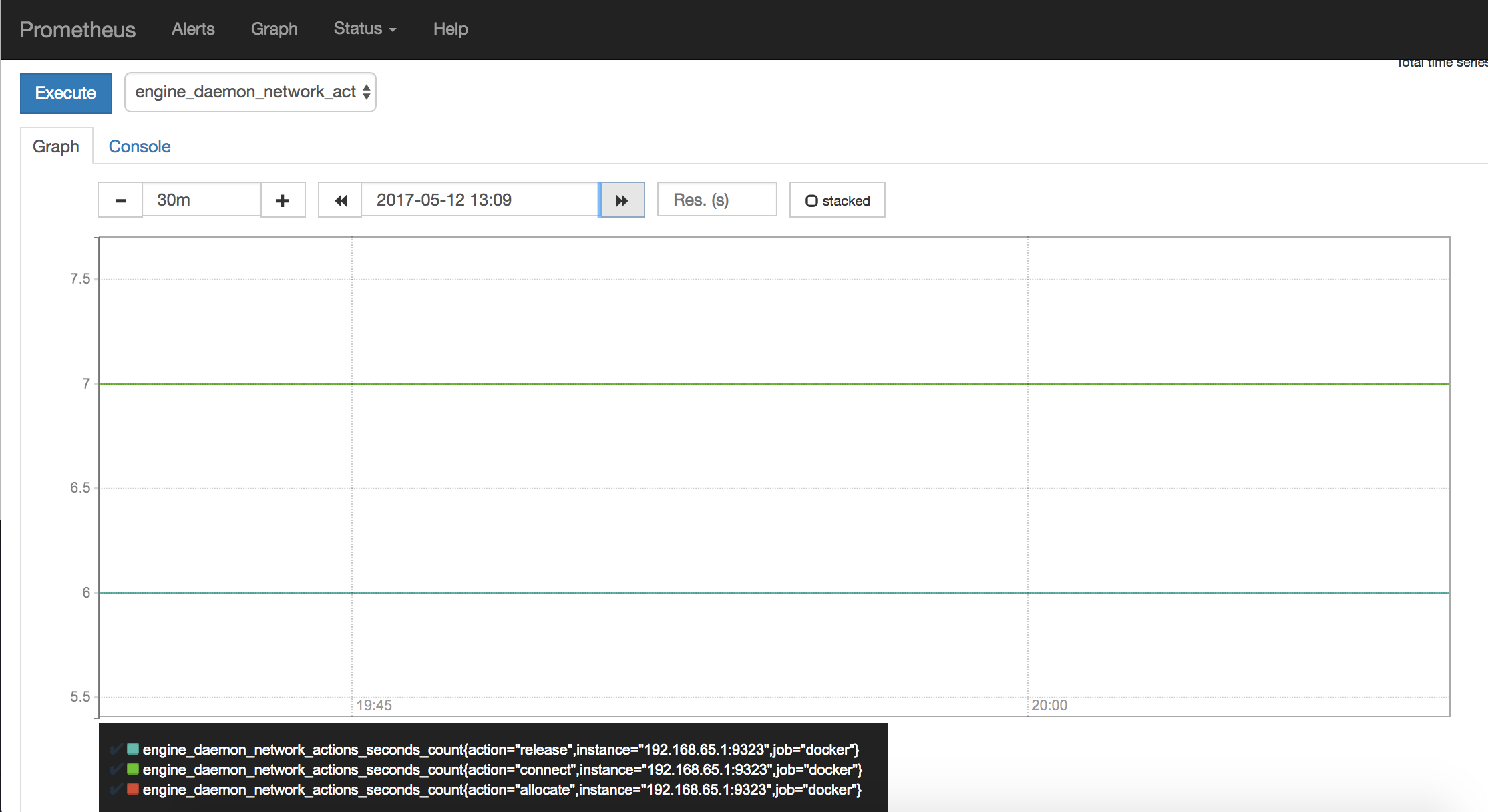
上のグラフは Docker インスタンスがアイドル状態であることを表わします。 作業をし始めると、このグラフは変化していきます。
このグラフが変化していくことを見るために、ネットワーク処理を生成してみます。 1 つのサービスに 10 個のタスクを用意し、Docker に対して停止なしに ping を打ち続けるようにします。 (ping 先は好きなように変更してください。)
$ docker service create \
--replicas 10 \
--name ping_service \
alpine ping docker.com
ほんの数分(デフォルトとした scrape interval 15 秒)待って、グラフを再表示してみます。
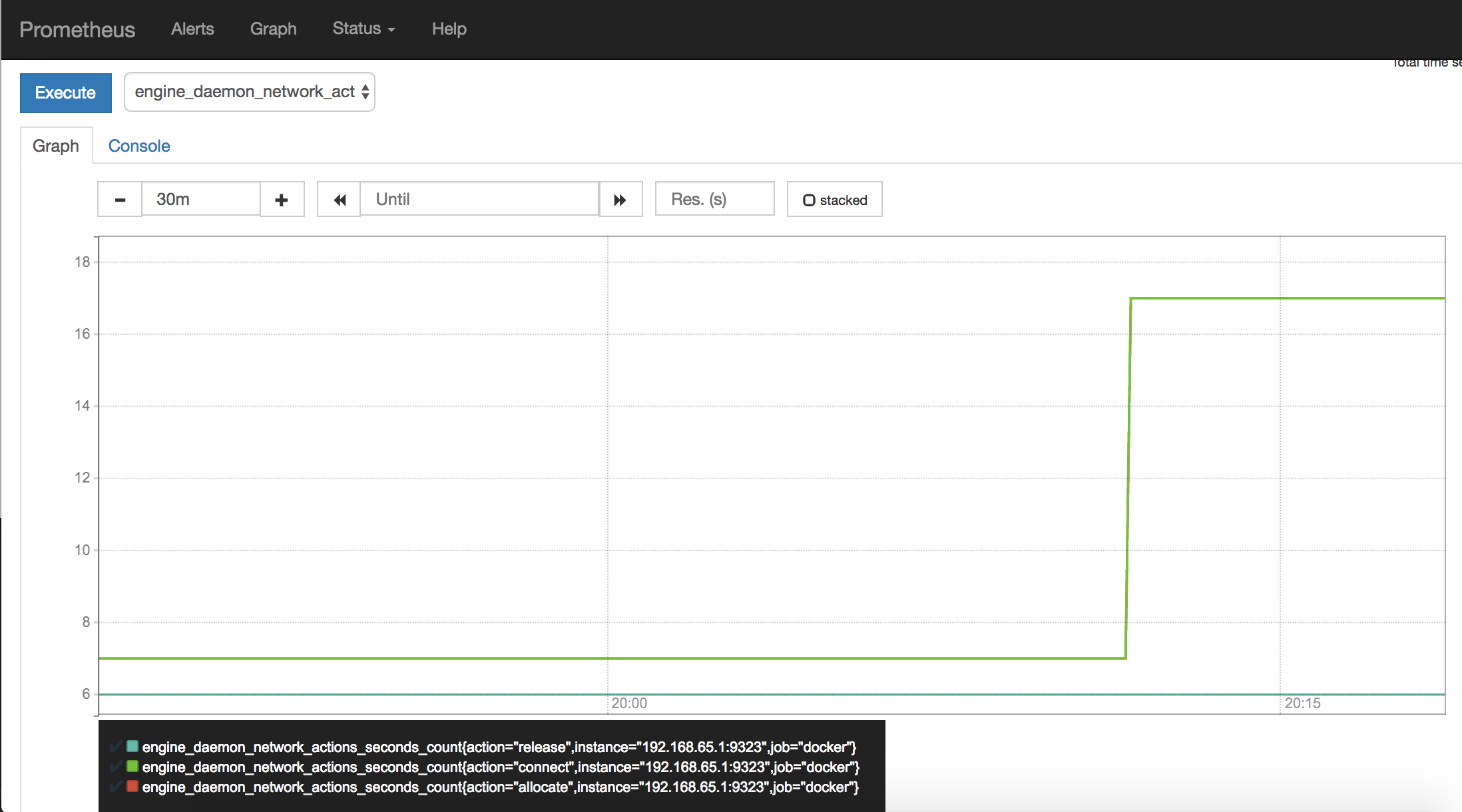
確認ができたら、サービスping_serviceを停止して削除します。
こうして、余計な ping によってホストが溢れないようにします。
$ docker service remove ping_service
しばらくしてみると、このグラフがまたアイドル状態に戻るはずです。
次のステップ
- Prometheus のドキュメント を読む。
- 警告 を設定してみる。