ノードの動作
Docker Engine 1.12 において導入された Swarm モードでは、1 つあるいは複数の Docker Engine からなるクラスター、つまり Swarm と呼ぶものが生成できるようになりました。 1 つの Swarm はいくつかのノードから構成されていて、物理マシン仮想マシンを問わず、Docker Engine 1.12 またはそれ以降が Swarm モードにおいて稼動します。
ノードには マネージャー と ワーカー という 2 つの種類があります。
Swarm モード概要 や 重要な考え方 をまだ読んでいない方は、ざっと目を通してください。
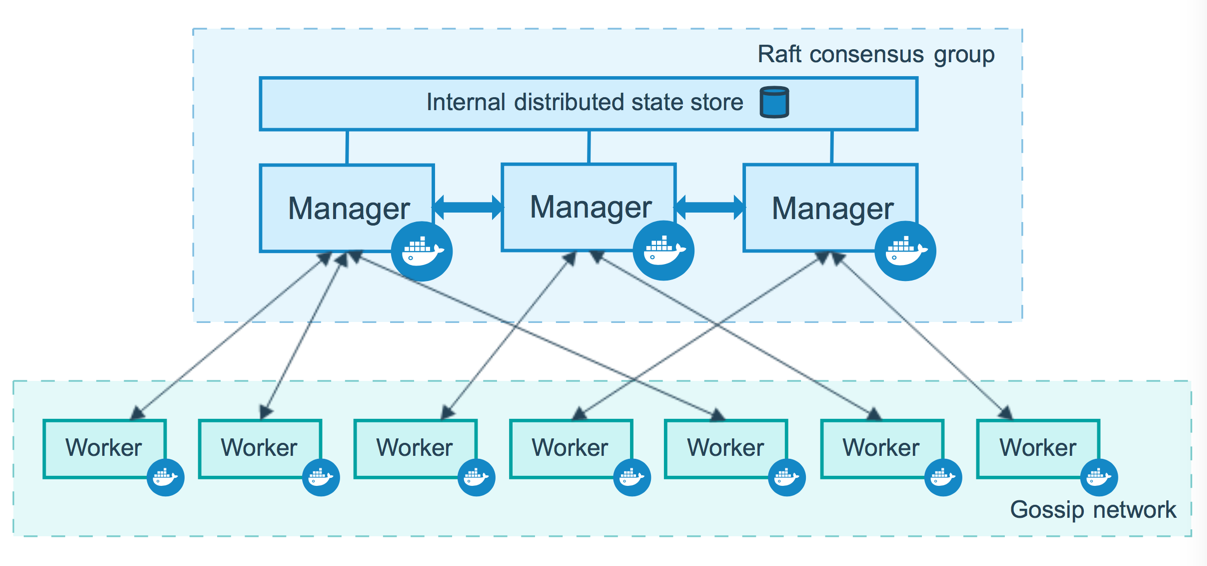
マネージャーノード
マネージャーノードはクラスター管理タスクを取り扱います。
- クラスター状態の管理。
- サービスのスケジュール管理。
- Swarm モードの HTTP API endpoints の提供。
マネージャーにおいては Raft を利用することによって、Swarm 全体を一貫した状態に保ちながら、そこに稼動するサービスをすべて管理します。 テスト目的であれば、1 つのマネージャーからなる 1 つの Swarm を実行することも可能です。 もっともただ 1 つのマネージャーしか持たない Swarm においてマネージャーが処理に失敗すると、サービスは稼動し続けますが、復旧のためにはもう 1 つ新たなクラスターを生成しなければなりません。
Swarm モードが持つ耐障害性(fault-tolerance)機能を活用するために、Docker では高可用性に関する開発方針に従って、奇数のノードを用意することを推奨しています。 複数のマネージャーを用意しておけば、マネージャーノードの 1 つに障害が発生しても、システムダウンをさせずに復旧することが可能になります。
- Swarm 内に 3 つのマネージャーがあれば、最大で 1 つのマネージャーの障害に耐えられます。
- Swarm 内に 5 つのマネージャーがあれば、最大かつ同時に 2 つのマネージャーの障害に耐えられます。
- Swarm 内に
N個のマネージャーがあれば、最大で(N-1)/2個のマネージャーの障害に耐えられます。 -
Docker では、1 つの Swarm に対して最大 7 つのマネージャーを持つことを推奨します。
重要事項 より多くのマネージャーを加えたからといって、スケーラビリティーや性能が向上するわけでは ありません。 一般的には、増やさないのが正しいことです。
ワーカーノード
ワーカーノードも Docker Engine のインスタンスです。 その唯一の目的はコンテナーを稼動させることです。 ワーカーノードは、Raft の分散状態の中には含まれず、スケジュール決定や Swarm モード HTTP API の提供も行いません。
1 つの Swarm においてマネージャーノードを 1 つだけとすることは可能ですが、1 つのマネージャーノードも存在しないところに 1 つだけワーカーノードを生成することはできません。
デフォルトで、マネージャーは同時にワーカーとしても動作します。
1 つのマネージャーノードしか持たないクラスターにおいては、docker service create といったコマンドを実行すると、スケジューラーはタスクのすべてをローカルの Engine に配置することになります。
複数ノードから構成される Swarm において、マネージャーに対してスケジューラーがタスクの割り当てを行わないようにするには、マネージャーノードの利用状態(availability)を Drain に設定します。
スケジューラーは Drain モードに設定されたノード上ではタスクを停止し、Active モードのタスクにはタスクをスケジューリングします。
スケジューラーは、利用状態が Drain であるようなノードに対しては、一切タスクを割り振ることはありません。
コマンドラインリファレンスの docker node update を参照して、ノードの利用状態の変更方法について確認してください。
ロールの変更
docker node promote を実行すれば、ワーカーノードをマネージャーノードに昇格させることができます。
たとえば、1 つのマネージャーノードを保守目的でオフラインとした場合には、別のワーカーノードを昇格させることが必要になる場合があります。
node promote を参照してください。
マネージャーノードをワーカーノードに降格させることもできます。 node demote を参照してください。