サービスの動作
Docker Engine が Swarm モードで稼動している場合、アプリケーションイメージのデプロイは、サービスを生成して行います。 サービスとしてよくあるのは、マイクロサービスを実現するイメージとして、一定規模のアプリケーションの内部に含まれます。 サービスの例としては、HTTP サーバーやデータベースがあります。 あるいは分散環境内において実行したいさまざまな実行プログラムがあります。
サービスを生成する際には、どのコンテナーイメージがこれを利用するのか、また実行コンテナー内ではどのようなコマンドを実行するのかを指定します。 そしてサービスに対しては、以下に示すようなオプションを定義します。
- Swarm の外部からサービスを利用するためのポート。
- Swarm 内において他サービスとのやりとりを行うための overlay ネットワーク。
- CPU やメモリに関する上限や確保。
- ローリングアップデートポリシー。
- Swarm 内において実行させるイメージのレプリカ数。
サービス、タスク、コンテナー
Swarm に対してサービスをデプロイすると、Swarm マネージャーはサービス定義を受け取ります。 そしてこれがサービスにとって望ましい状態が記されていることを解釈します。 マネージャーはこのサービスを Swarm 内ノードに向けて、複数のレプリカタスクとしてスケジューリングします。 タスクは Swarm内ノードの個々において独立して稼動します。
たとえば HTTP リスナーのインスタンスが 3 つあって、これらの間で負荷分散を行うとします。 以下の図では 1 つの HTTP サービスにおいて 3 つのレプリカがあることを示しています。 リスナーインスタンスの 3 つは、それぞれが Swarm におけるタスクの 1 つです。
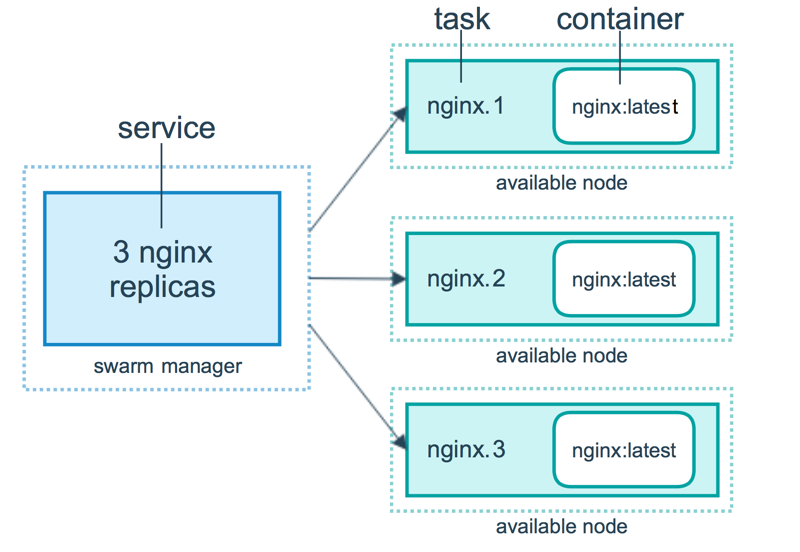
コンテナーは分離されたプロセスです。 Swarm モードモデルにおいては、各タスクから 1 つのコンテナーが呼び出されます。 タスクとは言ってみれば、スケジューラーがコンテナーを配置する「場所」のことです。 コンテナーが稼動していれば、スケジューラーはそこにあるタスクを起動状態にあるものとして認識します。 コンテナーがヘルスチェックに失敗したり終了したりすると、タスクは終了します。
タスクとスケジューリング
タスクとは Swarm 内においてスケジューリング対象となる最小単位のものです。 サービスの生成または更新を行って、そのサービスに期待する状態を宣言すると、オーケストレーターがスケジューリングされたタスクを通じて、期待される状態を実現します。 たとえばサービス定義として、オーケストレーターに対して HTTP リスナーを常時 3 インスタンス稼動し続けるようにしたとします。 オーケストレーターは、これに応じて 3 つのタスクを生成します。 各タスクは、コンテナーを起動させるものとしてスケジューラーが確保した「場所」です。 そしてコンテナーはタスクの実体です。 HTTP リスナーのタスクが連続してヘルスチェックに失敗するか、あるいはクラッシュしたとします。 そうなるとオーケストレーターは、新たなコンテナーを起動する新たなレプリカタスクを生成します。
タスクは一方向の動作を行う仕組みになっています。 その状態は、割り当て済(assigned)、準備済(prepared)、実行中(running)といったように、単調に進んでいきます。 タスクが処理に失敗すると、オーケストレーターはそのタスクとコンテナーを削除します。 そしてサービスに対して期待された状態とされる定義に従って、新たなタスクを生成し置き換えます。
Docker Swarm モードのベースにある考えとして、汎用目的のスケジューラーとオーケストレーターがあります。 抽象的なサービスやタスクというものがコンテナーを実現するわけですが、これらがコンテナーを認識しているわけではありません。 たとえばタスクは別の形で実装することも可能であって、それは仮想マシンのタスクやコンテナー化されていないプロセスタスクでも構わないのです。 スケジューラーやオーケストレーターとしては、タスクの種類は何であってもよいのですが、現行の Docker が対応するのは、コンテナータスクだけです。
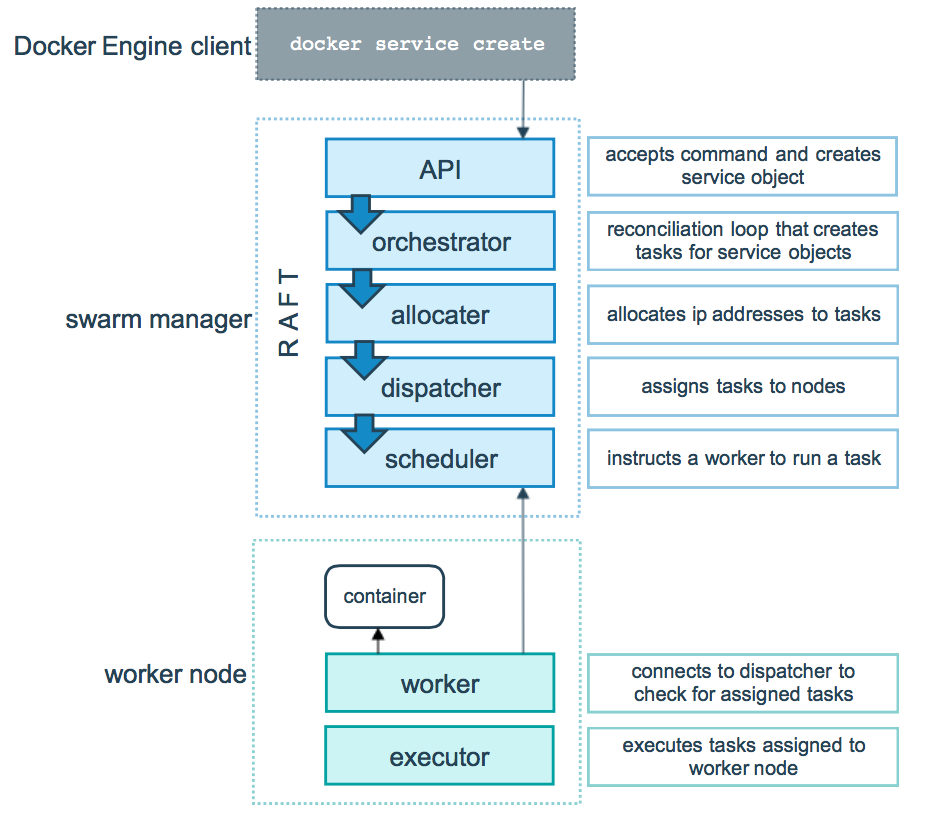
以下の図は、Swarm モードがどのようにしてサービス生成要求を受け入れて、ワーカーノードに向けてタスクをスケジューリングするかを示しています。
サービスの保留
サービス設定の仕方によっては、Swarm 内に現在あるノードすべてがタスクを起動しないようにすることができます。
そうした場合のサービスは保留(pending)という状態になります。
以下は、サービスが保留という状態を維持する例です。
メモ: 実現したいことが、サービスをデプロイしないようにするだけということであるなら、上のようにサービスを
pendingのままとする設定を行うのではなく、スケール値を 0 に設定してください。
-
ノードがすべて paused か drained である状態でサービスを生成すると、ノードが利用可能な状態になるまでは保留のままです。 実際には、利用可能になった最初のノードがすべてのタスクを受け入れることになるため、本番環境においてこうなることは望ましいことではありません。
-
サービスに対しては特定容量のメモリを予約することができます。 Swarm 内ノードにおいて、必要なメモリ容量を有するものが 1 つもない場合、サービスは保留状態のままであり、ノードがタスク実行可能な状態になるまで続きます。 この値に 500 GB のような非常に大きな値を設定していると、タスクはずっと保留のままとなり、その容量を持ったノードが実際に現れるまで続きます。
-
サービスに対しては配置に関する制約を課すことができます。 この制約は一定時間内に実現できない場合があります。
上のような動作からわかることは、タスクに対する条件や設定は、Swarm のその時点での状態と完全に一致するものではないということです。 Swarm の管理者として行うのは、Swarm において期待される状態を宣言するだけであり、これによって Swarm 内においてマネージャーが各ノードとともに状態を作り上げていくことになります。 そこでは Swarm 上のタスクに対して細かく制御をしていく必要はありません。
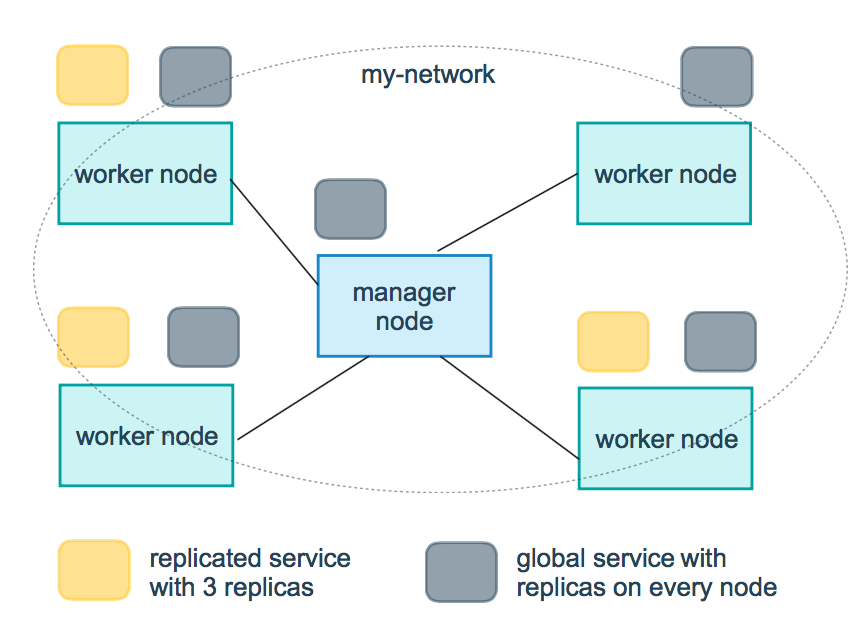
複製サービスとグローバルサービス
サービスのデプロイ形式には、複製(replicated)とグローバル(global)という 2 種類があります。
複製サービスの場合は、実行させたい複製タスク数を指定します。 たとえば HTTP サービスを 3 つのレプリカによりデプロイする場合、各レプリカは同一内容を提供します。
グローバルサービスは、各ノードごとに 1 つのタスクを実行するサービスです。 ここでは、あらかじめ指定されるタスク数というものはありません。 Swarm に対して新たなノードを追加すると、そのたびにオーケストレーターはタスクを生成して、スケジューラーはそのノードに対してタスクを割り当てます。 グローバルサービスが適しているのは、監視エージェント、アンチウィルススキャナーなど、Swarm 内の各ノードごとに実行させたいコンテナーの場合です。
以下の図では 3 つの複製サービスを黄色、1 つのグローバルサービスを灰色により表現しています。